
머신러닝 모델을 만들면 보통 이런 기대를 한다.
학습 데이터에서 잘 맞으면
새 데이터에서도 잘 맞겠지.
하지만 실제로는 그렇지 않을 수 있다.
모델이 학습 데이터에서는 거의 완벽한데, 처음 보는 데이터에서는 성능이 떨어지는 경우가 많다.
이 현상을 과적합(overfitting)이라고 한다.
과적합
과적합은 모델이 데이터의 일반적인 패턴이 아니라 학습 데이터에만 있는 우연한 흔들림과 노이즈까지 외워버리는 상태다.
예를 들어 학생이 시험공부를 한다고 하자.
- 좋은 공부:
- 문제의 원리를 이해한다.
- 새 문제가 나와도 풀 수 있다.
- 나쁜 공부:
- 기출문제 답만 외운다.
- 기출과 똑같은 문제는 맞힌다.
- 조금만 바뀌면 틀린다.
과적합된 모델은 두 번째 학생과 비슷하다.
학습 데이터라는 기출문제는 잘 맞히지만, 실제 운영에서 들어오는 새 데이터에는 약하다.
차원 데이터가 있다고 하자.
x가 증가하면 y도 대체로 증가한다. 그러나 데이터에는 약간의 노이즈가 있다.
이 데이터를 설명하는 모델을 세 가지로 생각해볼 수 있다.
- 과소적합
- 너무 단순한 직선 하나만 그린다.
- 데이터의 휘어진 패턴을 제대로 못 따라감
- 좋은 적합
- 전체적인 추세를 따라가는 부드러운 곡선을 그린다.
- 노이즈 하나하나에는 휘둘리지 않고 일반 패턴을 잡음
- 과적합
- 모든 점을 지나가려고 매우 구불구불한 선을 그린다.
- 학습 데이터에는 잘 맞지만 새 데이터에는 약함

과소적합과 과적합
| 구분 | 학습 데이터 성능 | 새 데이터 성능 | 원인 |
| 과소적합 | 낮음 | 낮음 | 모델이 너무 단순함 |
| 좋은 적합 | 높음 | 높음 | 일반 패턴을 잘 배움 |
| 과적합 | 매우 높음 | 낮음 | 학습 데이터의 노이즈까지 외움 |
핵심은 train 성능과 validation/test 성능의 차이다.
train 성능도 낮고 validation 성능도 낮다
→ 과소적합 가능성
train 성능은 높은데 validation 성능이 낮다
→ 과적합 가능성
왜 과적합이 생기는가
모델이 너무 복잡함
복잡한 모델은 데이터를 더 세밀하게 맞출 수 있다.
예를 들어 decision tree의 깊이가 너무 깊으면, 각 샘플을 거의 따로따로 외울 수 있다.
- 깊이 2인 트리: 큰 기준 몇 개로 나눔
- 깊이 30인 트리: 매우 세세한 조건까지 나눔
깊은 트리는 학습 데이터에는 잘 맞는다. 그러나 그 조건들이 실제 일반 패턴이 아니라 우연한 조합일 수 있다.
데이터가 적음
데이터가 적으면 모델이 일반 패턴과 노이즈를 구분하기 어렵다.
환불 문의 데이터가 20건뿐이다.
그중 15건에 "급해요"라는 단어가 있다.
모델은 "급해요"가 있으면 환불 문의일 가능성이 높다고 착각할 수 있다.
하지만 실제 운영에서는 배송 문의에도, 교환 문의에도 “급해요”가 나올 수 있다.
데이터가 적으면 우연한 상관관계를 진짜 패턴처럼 배울 위험이 커진다.
노이즈가 많음
라벨이 틀리거나 입력 데이터가 불안정하면 과적합이 쉬워진다.
실제 배송 문의인데 라벨이 환불 문의로 잘못 붙음
고객이 오타를 많이 냄
중복 데이터가 많음
비슷한 문장이 서로 다른 라벨을 가짐
모델이 이런 노이즈까지 억지로 맞추면 새 데이터 성능이 떨어진다.
Bias와 Variance
과적합/과소적합은 bias와 variance로도 설명할 수 있다.
- Bias
- 모델이 문제를 지나치게 단순하게 보는 경향
- bias가 높으면 복잡한 패턴을 못 잡음
- 모든 데이터를 직선 하나로만 설명하려고 함
- 이 경우 과소적합이 생기기 쉬움
- Variance
- 학습 데이터가 조금만 바뀌어도 모델이 크게 흔들리는 경향
- variance가 높으면 데이터의 작은 노이즈에도 민감하게 반응
- 학습 데이터의 점 하나가 바뀌면 곡선 모양이 크게 바뀜
- 이 경우 과적합이 생기기 쉬움
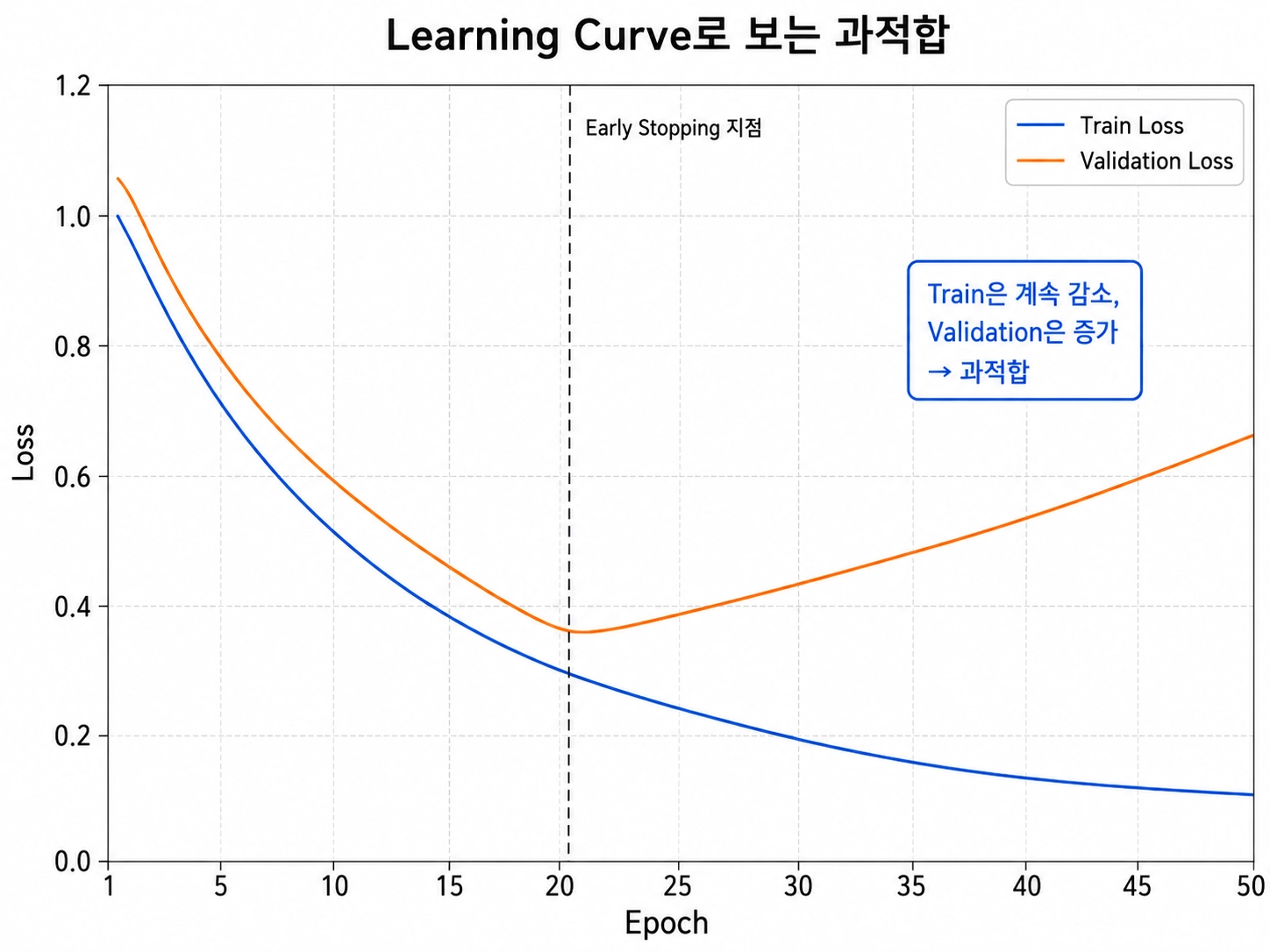
Learning Curve로 확인하기
Learning Curve는 학습 과정에서 train 성능과 validation 성능이 어떻게 변하는지 보는 그래프다.
- 좋은 학습
- train loss 감소
- validation loss 감소
- 둘 사이 차이가 크지 않음
- 모델이 일반 패턴을 배우고 있을 가능성이 높다.
- 과적합
- train loss는 계속 감소
- validation loss는 어느 순간부터 증가
- 모델이 학습 데이터에만 점점 더 맞춰지고 있다는 신호
- 과소적합
- train loss도 높음
- validation loss도 높음
- 둘 다 잘 줄지 않음
- 모델이 충분히 학습하지 못했거나, 모델이 너무 단순할 수 있다.
정규화란?
정규화(regularization)는 모델이 학습 데이터에 너무 복잡하게 맞춰지는 것을 막기 위해 복잡한 모델에 벌점을 주는 방법이다.
일반적인 학습 목표는 손실 최소화이지만, 정규화를 넣으면 목표가 바뀐다.
손실도 작게 만들고,
모델도 너무 복잡하지 않게 만든다.
$$
최종 목적함수 = 원래 손실 + 정규화 벌점
$$
즉 모델이 학습 데이터를 조금 더 잘 맞히려고 너무 복잡한 파라미터를 만들면, 그만큼 벌점을 받는다.
파라미터가 크다는 것은 무슨 뜻인가
선형 모델을 예로 보자.
$$
\hat{y} = w_1x_1 + w_2x_2 + b
$$
여기서 w1, w2가 가중치다. 가중치가 크면 작은 입력 변화에도 출력이 크게 흔들릴 수 있다.
w = 0.2
→ x가 조금 변해도 예측값이 조금 변함
w = 50
→ x가 조금만 변해도 예측값이 크게 변함
모든 경우에 큰 가중치가 나쁜 것은 아니지만
과도하게 큰 가중치는 모델이 학습 데이터의 세세한 흔들림에 민감하게 반응한다는 신호일 수 있다.
정규화는 이런 가중치를 억제한다.
L2 정규화
정의
L2 정규화는 가중치 제곱합에 벌점을 준다.
$$
Loss_{total} = Loss + \lambda \sum_i w_i^2
$$
λ(lambda): 정규화 강도
- λ가 작다 → 벌점 약함
- λ가 크다 → 벌점 강함
효과
L2는 큰 가중치에 강한 벌점을 준다.
w = 2 → w² = 4
w = 10 → w² = 100
가중치가 커질수록 벌점이 빠르게 커진다. 그래서 L2는 가중치를 전반적으로 작고 부드럽게 만든다.
특징을 완전히 버리기보다는
여러 특징을 조금씩 사용하게 만드는 경향
L1 정규화
정의
L1 정규화는 가중치 절댓값 합에 벌점을 준다.
$$
Loss_{total} = Loss + \lambda \sum_i |w_i|
$$
효과
L1은 일부 가중치를 정확히 0으로 만들 수 있다.
w1 = 0.8
w2 = 0
w3 = 0
w4 = 1.2
가중치가 0이 된 특징은 모델이 사용하지 않는 특징이 된다. 그래서 L1은 특징 선택(feature selection) 효과가 있다.
많은 특징 중 일부만 남기고 싶을 때 유용
L1과 L2 비교
구분L1L2
| 구분 | L1 | L2 |
| 벌점 | 가중치 절댓값 합 | 가중치 제곱합 |
| 효과 | 일부 가중치를 0으로 만듦 | 가중치를 전체적으로 작게 만듦 |
| 특징 선택 | 강함 | 약함 |
| 결과 | 희소한 모델 | 부드러운 모델 |

정규화 말고도 과적합을 줄이는 방법
- 더 많은 데이터
- 가장 직접적인 방법
- 데이터가 많아지면 모델이 우연한 패턴과 일반 패턴을 구분하기 쉬워진다.
- 하지만 항상 더 많은 라벨 데이터를 얻을 수 있는 것은 아니다.
- Early Stopping
- validation 성능이 더 이상 좋아지지 않으면 학습을 멈춘다.
- train loss는 계속 내려가도 validation loss가 올라가기 시작하면 멈춤
- 딥러닝이나 boosting 모델에서 자주 쓴다.
- Dropout
- 신경망에서 일부 뉴런을 학습 중 랜덤하게 꺼버리는 방법
- 매번 모든 뉴런에 의존하지 못하게 함
- 여러 부분 표현을 함께 쓰도록 유도
- 특정 뉴런 조합을 외우는 것을 줄이는 효과가 있다.
- Data Augmentation
- 기존 데이터를 변형해서 학습 데이터를 늘리는 방법이다.
- 이미지에서는 흔히 사용한다.
- 좌우 반전 / 작은 회전 / 밝기 변화 / 잘라내기
- 텍스트에서는 더 조심해야 한다.(문장을 조금 바꿨는데 라벨 의미가 달라질 수 있기 때문)
- Tree Pruning
- Decision Tree가 너무 깊게 자라지 않도록 제한한다.
- e.g) max_depth 제한, min_samples_leaf 설정,
min_samples_split 설정 - 트리는 깊어질수록 학습 데이터를 세밀하게 외우기 쉬우므로, 깊이와 리프 조건을 조절해야 한다.
| 모델 | 과적합 방지 방법 |
| Linear/Logistic Regression | L1, L2 정규화 |
| Decision Tree | max_depth, min_samples_leaf |
| Random Forest | 트리 수 증가, depth 제한, 특징 샘플링 |
| Gradient Boosting | learning_rate 감소, early stopping, depth 제한 |
| Neural Network | dropout, weight decay, early stopping |
| KNN | 너무 작은 k 피하기 |
실무 체크리스트
- train 성능과 validation 성능 차이가 큰가?
- validation loss가 어느 순간부터 증가하는가?
- 모델이 데이터 크기에 비해 너무 복잡한가?
- 라벨 오류나 중복 데이터가 많은가?
- 정규화 강도를 높이면 validation 성능이 좋아지는가?
- tree depth나 boosting iteration을 줄이면 좋아지는가?
- early stopping 지점이 있는가?
정리
- 과적합은 모델이 일반 패턴이 아니라 학습 데이터의 노이즈까지 외운 상태.
- 정규화는 손실함수에 복잡도 벌점을 추가해 모델이 너무 복잡해지는 것을 막는다.
- 학습 데이터만 잘 맞히는 모델이 아니라 처음 보는 데이터에서도 적당히 잘 맞는 모델을 만드는 것이 목표.
GitHub 댓글