
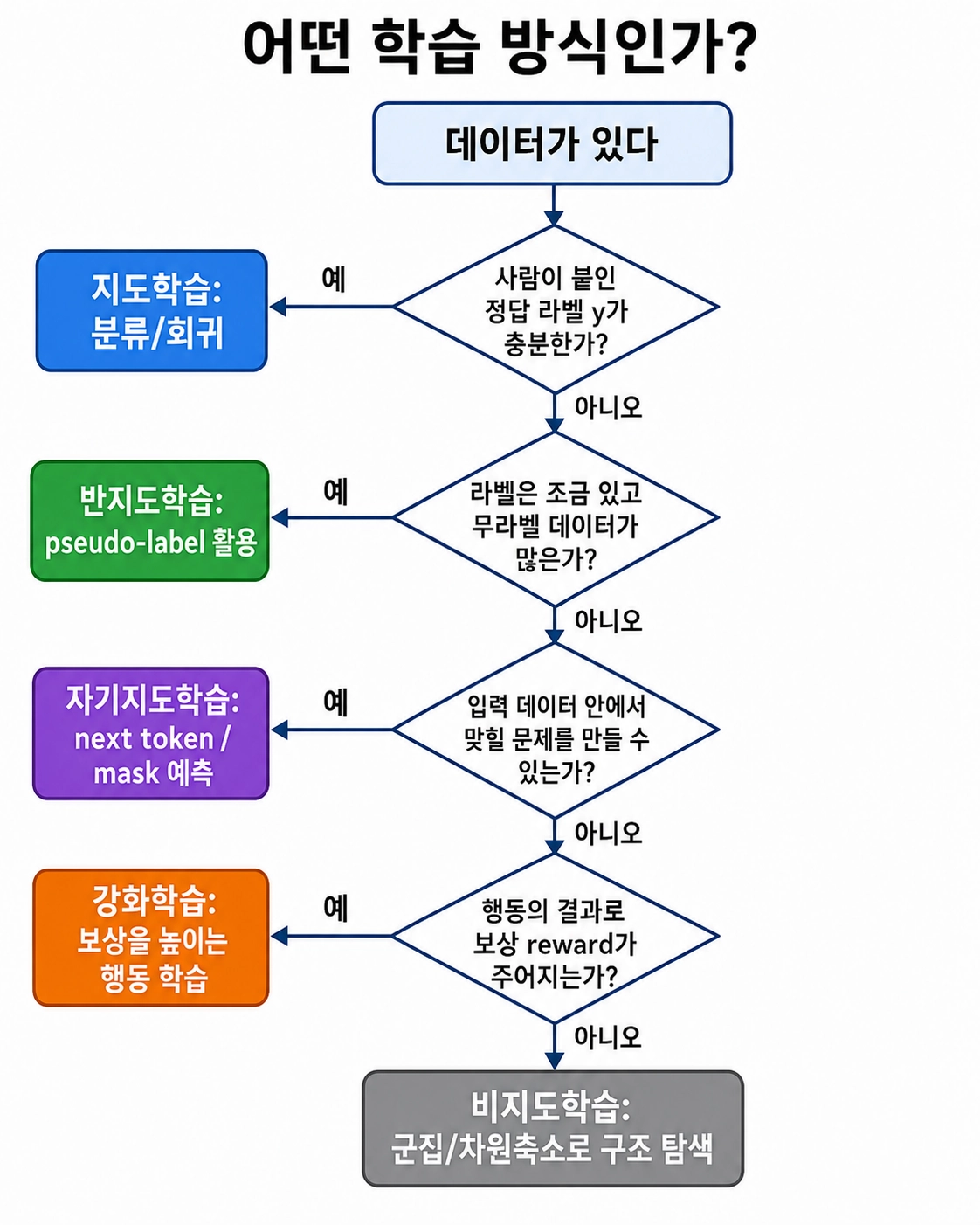
머신러닝 문제를 처음 볼 때 가장 먼저 확인할 것
정답 라벨이 있느냐?
정답 라벨이 있으면 지도학습에 가깝다.
정답 라벨이 없고 데이터의 구조를 찾는다면 비지도학습에 가깝다.
라벨이 조금만 있거나, 데이터 자체에서 학습 문제를 만들거나, 행동에 대한 보상을 통해 배우는 경우도 있다.
- 지도학습: 입력과 정답이 함께 있는가?
- 비지도학습: 정답 없이 데이터 구조를 찾는가?
- 반지도학습: 라벨 있는 데이터가 적고, 라벨 없는 데이터가 많은가?
- 자기지도학습: 데이터 자체에서 맞혀야 할 문제를 만들 수 있는가?
- 강화학습: 행동의 결과로 보상을 받고, 장기 보상을 키우는가?
전체 기준
머신러닝 문제는 보통 다음 순서로 생각하면 된다.
1. 정답 y가 있는가?
→ 있다: 지도학습
→ 없다: 다음 질문
2. 데이터끼리 구조를 찾고 싶은가?
→ 그렇다: 비지도학습
3. 라벨은 조금 있고, 라벨 없는 데이터가 많은가?
→ 그렇다: 반지도학습
4. 데이터 일부를 가리거나 변형해서 맞히게 할 수 있는가?
→ 그렇다: 자기지도학습
5. 정답이 아니라 행동의 결과로 보상이 주어지는가?
→ 그렇다: 강화학습
중요한 점은, 이 분류들은 완전히 서로 배타적인 상자가 아니라는 것. 실제 시스템에서는 여러 방식을 조합할 수 있다.
e.g.
LLM 사전학습: 자기지도학습
LLM 지시 따르기 파인튜닝: 지도학습
RLHF: 강화학습 계열 아이디어 포함
RAG 시스템 평가 데이터 구축: 지도학습적 평가 세트 활용
지도학습(Supervised Learning)
정의
지도학습은 입력 데이터와 정답 라벨이 함께 있는 상태에서 학습하는 방식이다.
입력 x → 정답 y
모델은 입력을 보고 정답에 가까운 출력을 내도록 학습한다.
왜 “지도”학습인가
여기서 지도는 선생님이 옆에서 답을 알려주는 상황에 가깝다.
입력: "배송이 너무 늦어요"
정답: 배송 지연 문의
모델이 처음에 틀리게 예측해도 정답이 있다.
모델 예측: 환불 문의
실제 정답: 배송 지연 문의
모델은 이 차이를 손실함수로 계산하고, 다음에는 정답에 더 가까워지도록 파라미터를 조정한다.
지도학습의 핵심 구조
학습 데이터:
(x1, y1), (x2, y2), (x3, y3), ...
목표:
새로운 x가 들어왔을 때 적절한 y를 예측하기
e.g)
| 입력 x | 정답 y |
| "배송이 안 와요" | 배송 지연 |
| "환불하고 싶어요" | 환불 문의 |
| "상품을 바꾸고 싶어요" | 교환 문의 |
모델은 이 예시들을 보고 새로운 문장이 들어왔을 때 분류한다.
입력: "택배가 아직 도착하지 않았습니다"
예측: 배송 지연
지도학습의 대표 문제 1 - 분류
분류는 정해진 클래스 중 하나를 고르는 문제다.
입력 → 클래스
e.g)
| 문제 | 입력 | 출력 |
| CS 문의 분류 | 문의 문장 | 배송 / 환불 / 교환 |
| 스팸 탐지 | 이메일 | 스팸 / 정상 |
| 리뷰 감성 분석 | 리뷰 문장 | 긍정 / 부정 |
| 이미지 분류 | 사진 | 고양이 / 강아지 / 자동차 |
분류 문제의 출력은 보통 확률로 나온다.
배송 지연: 0.82
환불 문의: 0.12
교환 문의: 0.04
기타: 0.02
가장 높은 확률의 클래스를 최종 예측으로 사용할 수 있다.
지도학습의 대표 문제 2 - 회귀
회귀는 연속적인 숫자를 예측하는 문제다.
입력 → 숫자
e.g:
| 문제 | 입력 | 출력 |
| 집값 예측 | 면적, 위치, 연식 | 가격 |
| 매출 예측 | 광고비, 방문자 수 | 매출액 |
| 배송 시간 예측 | 거리, 물류 상태 | 예상 배송 시간 |
| 온도 예측 | 날짜, 지역, 기압 | 온도 |
분류와 다른 점은 출력이 클래스가 아니라 숫자라는 것이다.
분류: 배송 / 환불 / 교환 중 하나
회귀: 3.7일, 128000원, 0.83 같은 숫자
지도학습이 잘 맞는 상황
지도학습은 다음 조건일 때 강하다.
- 정답 라벨이 충분히 있다
- 미래에도 비슷한 형태의 데이터가 들어온다
- 예측해야 할 목표가 명확하다
- 오답을 손실함수로 계산할 수 있다
- e.g) 과거 문의 문장과 담당자 분류 결과가 많이 있다. → 새 문의를 자동 분류하는 모델 학습 가능
지도학습의 한계
지도학습은 라벨이 필요한데, 문제는 라벨을 만드는 데 비용이 든다는 것이다.
만약 데이터가 10만건이라면, 사람이 하나씩 배송/환불/교환으로 라벨링해야 한다.
→ 시간과 비용이 큼
또한 라벨 품질이 낮으면 모델도 잘못 배운다.
잘못된 정답 라벨 → 잘못된 패턴 학습 → 실제 예측도 흔들림
비지도학습(Unsupervised Learning)
정의
비지도학습은 정답 라벨 없이 데이터의 구조를 찾는 학습 방식이다.
- 입력 x만 있음
- 정답 y는 없음
모델은 “이 데이터의 정답이 무엇인지”를 배우는 게 아니라, 데이터끼리의 관계를 찾는다.
- 어떤 데이터들이 서로 비슷한가?
- 어떤 데이터들이 멀리 떨어져 있는가?
- 데이터는 몇 개의 큰 덩어리로 나뉘는가?
- 고차원 데이터를 낮은 차원으로 줄이면 어떤 구조가 보이는가?
비지도학습은 “아무 목표도 없는 학습”이 아니다
비지도학습에는 정답 라벨이 없지만, 목표가 아예 없는 것은 아니다.
예를 들어 K-Means와 SVD 차원축소는 다음 목표를 가진다.
- K-Means
- 같은 군집 안의 점들은 가깝게
- 다른 군집의 점들은 상대적으로 멀게
- SVD 차원축소
- 원본 데이터의 주요 구조를 최대한 보존하면서 차원을 줄이기
즉, 비지도학습은 정답 y가 없는 상태에서 구조를 찾는 것이지, 아무 계산이나 하는 것은 아니다.
비지도학습의 대표 문제 1 - 클러스터링
- 클러스터링: 비슷한 데이터끼리 묶는 작업
- e.g) 수만 개의 CS문의 제목 → 비슷한 표현끼리 자동으로 묶기
- 결과
- 군집 1: 배송 지연 관련 문의
- 군집 2: 환불 요청 관련 문의
- 군집 3: 제품 파손 관련 문의
- 군집 4: 쿠폰/결제 관련 문의
- 중요한 점: 모델은 군집 1이 "배송 지연"이라고 이름 붙여주지 않는다.
- “이 데이터들이 서로 가깝다”까지만 알려준다.
- 그 군집이 어떤 의미인지는 사람이 보고 해석해야 한다.
비지도학습의 대표 문제 2 - 차원축소
- 차원축소: 높은 차원의 데이터를 낮은 차원으로 줄이는 작업
- e.g) TF-IDF 벡터: 8000차원 → SVD로 100차원으로 축소
- 왜 줄이는가?
- 계산을 빠르게 하기 위해
- 시각화하기 위해
- 노이즈를 줄이기 위해
- 고차원 거리 문제를 완화하기 위해
- 차원축소는 단순히 데이터를 버리는 게 아니라, 가능한 한 중요한 구조를 보면서 압축하는 것
비지도학습이 잘 맞는 상황
- 정답 라벨이 없다
- 데이터를 먼저 탐색하고 싶다
- 숨은 패턴을 찾고 싶다
- 비슷한 것끼리 묶고 싶다
- 시각화하거나 압축하고 싶다
새로운 유형의 문의가 계속 쌓인다
정답 라벨은 없다
→ 클러스터링으로 비슷한 문의 묶음부터 찾는다
비지도학습의 한계
비지도학습 결과는 해석이 필요하다.
예를 들어 군집이 5개 나왔다면, 그 5개가 실무적으로 의미 있는지는 별도 판단이 필요하다.
또한 평가도 어렵다.
지도학습처럼 “정답과 비교해서 정확도 92%”라고 말하기 어렵다.
그래서 실루엣 스코어 같은 지표를 쓰지만, 최종적으로는 사람이 데이터 샘플을 확인해야 한다.
지도학습과 비지도학습 비교
구분 지도학습 비지도학습
| 구분 | 지도학습 | 비지도학습 |
| 정답 라벨 | 있음 | 없음 |
| 목표 | 입력에 대한 정답 예측 | 데이터 구조 발견 |
| 대표 문제 | 분류, 회귀 | 클러스터링, 차원축소 |
| 평가 | 정답과 비교 가능 | 간접 지표와 샘플 검토 필요 |
| 예시 | 문의 유형 자동 분류 | 비슷한 문의끼리 묶기 |
| 결과 해석 | 비교적 명확 | 사람이 의미를 붙여야 함 |
반지도학습(Semi-Supervised Learning)
정의
반지도학습은 라벨 있는 데이터는 적고, 라벨 없는 데이터는 많을 때 사용하는 학습 방식이다.
라벨 있는 데이터 1,000개
라벨 없는 데이터 100,000개
지도학습처럼 라벨을 쓰지만, 비지도학습처럼 라벨 없는 데이터도 함께 활용한다.
그래서 “반지도”라고 부른다.
왜 필요한가
실무에서는 원본 데이터는 많이 쌓여 있지만, 사람이 정답 라벨을 붙인 데이터는 적은 경우가 많다.
예를 들어 고객 문의 원본이 50만 건, 담당자가 유형 라벨을 붙인 문의가 3천 건이라고 하자.
벨 3천 건만으로 지도학습을 하면 데이터가 부족할 수 있다.
하지만 라벨 없는 50만 건을 버리기엔 아깝다.
반지도학습은 이 라벨 없는 데이터를 학습에 활용하려는 방법이다.
대표 방식 - Pseudo Labeling
Pseudo labeling은 가장 직관적인 반지도학습 방식이다.
흐름은 다음과 같다.
- 라벨 있는 데이터로 모델을 먼저 학습힌다.
- 학습된 모델로 라벨 없는 데이터를 예측한다.
- 모델이 높은 확신을 가진 예측만 가짜 라벨로 사용한다.
- 원래 라벨 데이터 + 가짜 라벨 데이터를 합쳐 다시 학습한다.
작은 예시
라벨 있는 데이터:
"배송이 늦어요" → 배송 지연
"환불하고 싶어요" → 환불 문의
"상품을 바꾸고 싶어요" → 교환 문의
이 데이터로 모델을 먼저 학습한다.
그다음 라벨 없는 문장을 모델에 넣는다.
입력: "택배가 아직 안 왔어요"
모델 예측:
배송 지연 0.94
환불 문의 0.04
교환 문의 0.02
확신도가 높다. 이 경우 가짜 라벨을 붙일 수 있다.
"택배가 아직 안 왔어요" → 배송 지연
반대로 이런 경우는 조심해야 한다.
입력: "주문 취소하고 다시 결제하고 싶어요"
모델 예측:
환불 문의 0.45
결제 문의 0.39
기타 0.16
확신도가 낮다. 이런 데이터를 가짜 라벨로 넣으면 오히려 모델이 잘못 배울 수 있다.
Confidence Threshold
Pseudo labeling에서는 보통 임계값을 둔다.
예측 확률 0.9 이상만 가짜 라벨로 사용
임계값이 너무 낮으면 잘못된 가짜 라벨이 많아진다.
임계값이 너무 높으면 사용할 수 있는 데이터가 너무 적어진다.
- 낮은 threshold → 데이터는 많지만 오류 위험 큼
- 높은 threshold → 데이터는 적지만 품질은 높음
반지도학습의 위험
가짜 라벨이 틀렸는데 그걸 정답처럼 학습하면 문제가 된다.
잘못된 예측 → 잘못된 가짜 라벨 → 다시 학습 → 모델이 더 강하게 잘못 배움
이걸 오류 누적이라고 볼 수 있다.
그래서 반지도학습은 “라벨 없는 데이터를 많이 쓰니까 무조건 좋다”가 아니다.
가짜 라벨 품질 관리가 핵심이다.
Active Learning과의 차이
반지도학습과 헷갈리는 개념이 active learning이다.
| 구분 | 반지도학습 | Active Learning |
| 핵심 | 모델이 라벨 없는 데이터에 가짜 라벨을 붙임 | 모델이 사람에게 물어볼 데이터를 고름 |
| 사람 개입 | 적음 | 있음 |
| 목표 | 라벨 없는 데이터 자동 활용 | 라벨링 비용을 줄이면서 좋은 샘플 선택 |
Active learning은 보통
모델이 헷갈리는 데이터 찾기 → 사람에게 그 데이터만 라벨링 요청 → 적은 라벨링으로 성능 개선
의 흐름이다.
자기지도학습(Self-Supervised Learning)
정의
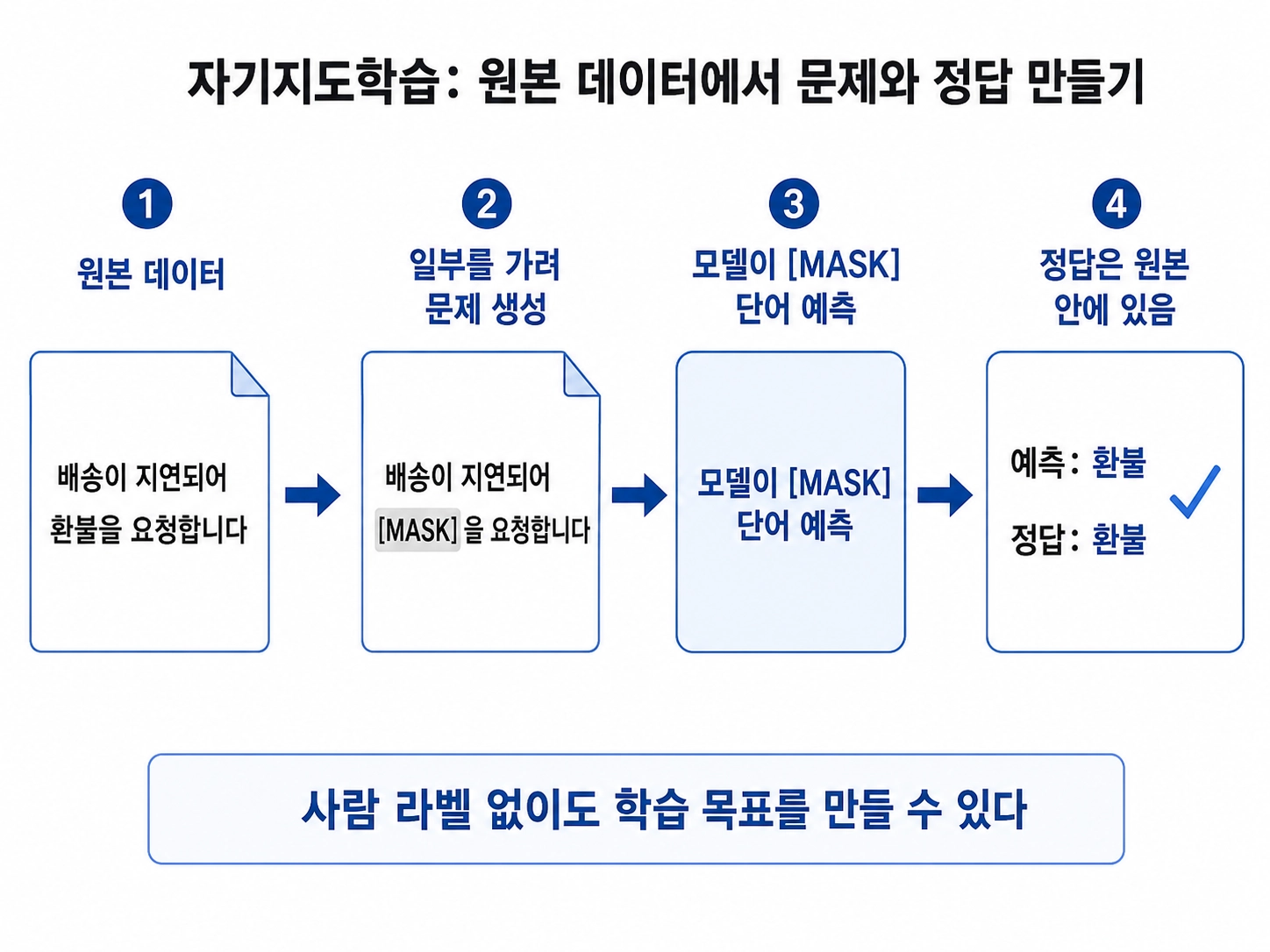
자기지도학습은 사람이 정답 라벨을 붙이지 않고, 데이터 자체에서 정답처럼 사용할 문제를 만들어 학습하는 방식이다.
핵심은,
원본 데이터가 있다.
→ 일부를 가리거나 변형한다.
→ 모델에게 원래 무엇이었는지 맞히게 한다.
→ 정답은 원본 데이터 안에 이미 있다.
사람이 직접 "이 문장은 환불 문의다", "이 이미지는 고양이다", "이 문장 쌍은 같은 의미다" 와 같은 라벨을 붙이지 않는다.
대신 원본 데이터 안에서 맞혀야 할 목표를 만든다.
왜 “자기지도”라고 부르는가
지도학습은 사람이 정답을 준다.
입력: "배송이 너무 늦어요"
정답: 배송 지연 문의
자기지도학습은 사람이 정답을 주지 않는다.
대신 데이터 안에서 정답을 만든다.
원본 문장:
"배송이 지연되어 환불을 요청합니다"
모델에게 보여주는 입력:
"배송이 지연되어 [MASK]을 요청합니다"
모델이 맞혀야 하는 정답:
"환불"
여기서 `환불`이라는 정답은 사람이 새로 붙인 라벨이 아니다.
원래 문장 안에 있던 단어를 잠깐 가렸을 뿐이다.
그래서 자기지도학습은 사람이 만든 정답표는 없지만, 데이터 자체를 이용해서 맞혀야 할 문제를 만든다고 볼 수 있다.
가짜 문제를 푸는 이유
자기지도학습에서 만드는 문제를 보통 pretext task, 즉 사전 과제라고 부른다.
이 문제 자체가 최종 목적은 아닐 수 있다.
예를 들어 `[MASK]` 단어 맞히기가 최종 서비스 기능은 아니다.
중요한 건 문제를 푸는 과정에서 모델이 데이터의 구조를 배운다는 점이다.
예:
"고객님, 주문하신 상품의 [MASK]이 지연되고 있습니다."
모델이 [MASK]를 맞히려면 후보 단어의 문맥을 이해해야 한다.
배송
출고
도착
환불
결제
문맥상 자연스러운 단어는 배송, 출고, 도착 쪽이다.
환불, 결제도 CS 도메인 단어지만 이 문장에서는 덜 자연스럽다.
이런 문제를 수많은 문장으로 반복하면 모델은 다음을 배운다.
- 단어들이 어떤 문맥에서 같이 쓰이는지
- 문장 구조가 어떻게 이어지는지
- 표현이 달라도 의미가 비슷한 경우가 무엇인지
- 문맥상 자연스러운 다음 단어가 무엇인지
예시 1 - Masked Language Modeling
BERT 계열 모델에서 자주 쓰인 방식이다.
학습 방식
문장의 일부 단어를 가린다.
모델은 가려진 단어를 맞힌다.
원본:
"고객이 환불을 요청했다"
입력:
"고객이 [MASK]을 요청했다"
정답:
"환불"
모델이 배우는 것
모델은 `요청했다` 앞에 어떤 단어가 자연스러운지 배운다.
환불을 요청했다
교환을 요청했다
취소를 요청했다
상담을 요청했다
또 `고객이`라는 주어와 `요청했다`라는 동사 사이에서 어떤 명사가 자주 오는지도 학습한다.
이런 패턴이 쌓이면 모델은 단어의 의미와 문맥을 어느 정도 구분하게 된다.
사용 예시
이렇게 사전학습한 모델은 다음 작업에 활용할 수 있다.
- 문장 분류
- 질문 답변
- 문서 검색
- 개체명 인식
- 문장 임베딩
예시 2 - Next Token Prediction
GPT 같은 생성형 언어모델에서 쓰는 방식이다.
학습 방식
지금까지의 토큰을 보고 다음 토큰을 맞힌다.
입력:
"고객님, 주문하신 상품의"
정답:
"배송"
그다음에는 정답까지 포함해서 다시 다음 토큰을 맞힌다.
입력:
"고객님, 주문하신 상품의 배송"
정답:
"이"
이 과정을 반복한다.
고객님, 주문하신 상품의
→ 배송
고객님, 주문하신 상품의 배송
→ 이
고객님, 주문하신 상품의 배송이
→ 지연
모델이 배우는 것
모델은 다음을 배운다.
- 단어 순서
- 문장 구조
- 자주 이어지는 표현
- 문맥상 자연스러운 답변
- 말투와 문체
- 도메인별 표현 방식
그래서 LLM은 단어를 아무렇게나 이어 붙이는 게 아니다.
지금까지의 문맥에서 다음에 올 가능성이 높은 토큰을 계속 예측하면서 문장을 생성한다.
예시 3 - Contrastive Learning
검색용 임베딩 모델이나 이미지-텍스트 모델에서 자주 쓰이는 방식이다.
학습 방식
비슷한 쌍은 가깝게, 다른 쌍은 멀게 만든다.
예를 들어 같은 의미의 문장 쌍이 있다고 하자.
문장 A:
"배송이 너무 늦어요"
문장 B:
"상품이 아직 도착하지 않았어요"
두 문장은 표현은 다르지만 의미는 비슷하다.
모델은 두 문장의 벡터가 가까워지도록 학습한다.
반대로 의미가 다른 문장은 멀어지게 한다.
문장 C:
"결제 수단을 변경하고 싶어요"
학습 목표는 이렇게 정리할 수 있다.
A와 B는 가깝게
A와 C는 멀게
B와 C는 멀게
모델이 배우는 것
모델은 단어가 완전히 같지 않아도 의미가 비슷한 문장을 가까운 벡터로 배치하는 법을 배운다.
그래서 검색에서 이런 일이 가능해진다.
검색어:
"택배가 안 와요"
찾아야 할 문서:
"배송 지연으로 인한 보상 기준"
키워드는 다르지만 의미가 연결되어 있으므로 임베딩 검색에서 가까운 결과로 나올 수 있다.
자기지도학습과 비지도학습의 차이
둘 다 사람이 라벨을 붙이지 않는다는 점에서는 비슷하다.
하지만 학습 목표가 다르다.
| 구분 | 비지도학습 | 자기지도학습 |
| 사람 라벨 | 없음 | 없음 |
| 학습 목표 | 데이터 구조 찾기 | 데이터 안에서 만든 문제 맞히기 |
| 예시 | 클러스터링, 차원축소 | 다음 토큰 예측, 가려진 단어 맞히기 |
| 출력 | 군집, 축소 벡터 등 | 사전학습된 표현/모델 |
- 비지도학습: 정답 없이 데이터 구조를 찾는다.
- 자기지도학습: 사람 라벨은 없지만, 데이터 자체로 만든 정답을 맞힌다.
왜 중요한가
현대 AI에서 자기지도학습이 중요한 이유는 단순하다.
- 라벨 있는 데이터는 비싸다.
- 라벨 없는 데이터는 많다.
사람이 모든 문장, 이미지, 음성에 정답을 붙이는 건 비용이 크다.
하지만 원본 데이터는 훨씬 많다. 웹 문서, 사내 문서, 로그, 이미지, 음성, 코드 등.
자기지도학습은 이 많은 원본 데이터를 이용해서 모델을 먼저 학습시킨다.
대량의 라벨 없는 데이터
→ 자기지도학습으로 사전학습
→ 언어/이미지/패턴에 대한 기본 표현 학습
→ 적은 라벨 데이터로 특정 작업에 맞게 조정
이 흐름이 사전학습(pretraining)과 파인튜닝(fine-tuning)의 기본 구조다.
강화학습(Reinforcement Learning)
정의
강화학습은 행동의 결과로 보상을 받고, 장기적으로 더 큰 보상을 얻도록 학습하는 방식이다.
지도학습처럼 매 순간 정답 라벨이 주어지지 않는다.
대신 어떤 행동을 했을 때 결과가 좋았는지 나빴는지를 보상으로 받는다.
상태를 본다
→ 행동을 선택한다
→ 환경이 반응한다
→ 보상을 받는다
→ 다음에는 더 좋은 행동을 선택하도록 조정한다
기본 구성요소
| 의미 | 요소 | 예시 |
| Agent | 행동을 선택하는 주체 | 게임 AI, 로봇, 추천 시스템 |
| Environment | agent가 상호작용하는 세계 | 게임 맵, 실제 공간, 사용자 반응 |
| State | 현재 상황 | 현재 위치, 점수, 사용자 상태 |
| Action | 선택 가능한 행동 | 이동, 클릭 추천, 답변 선택 |
| Reward | 행동 결과로 받는 점수 | 승리 +1, 실패 -1, 클릭 +1 |
| Policy | 상태에서 행동을 고르는 전략 | 이 상황에서는 어떤 행동을 할지 |
지도학습과의 차이
지도학습에서는 정답이 바로 주어진다.
입력: 이미지
정답: 고양이
강화학습에서는 정답 행동이 바로 주어지지 않는다.
현재 상태: 미로의 한 칸
행동 후보: 위 / 아래 / 왼쪽 / 오른쪽
정답: 알려주지 않음
보상: 나중에 목표 지점에 도착하면 +1
모델은 직접 행동해보고, 결과로 받은 보상을 통해 어떤 행동이 좋은지 배운다.
즉시 보상과 장기 보상
강화학습이 어려운 이유는 좋은 행동의 결과가 바로 나타나지 않을 수 있기 때문이다.
e.g) 체스에서 지금 말 하나를 희생함
→ 당장은 손해처럼 보임
→ 5수 뒤에 체크메이트 가능
즉시 보상만 보면 나쁜 행동처럼 보이지만, 장기적으로는 좋은 행동일 수 있다.
강화학습은 현재의 보상만이 아니라 미래의 보상까지 고려해야 한다.
탐험과 활용
강화학습의 핵심 딜레마는 exploration vs exploitation이다.
- 탐험(exploration): 아직 잘 모르는 행동을 시도해봄
- 활용(exploitation): 지금까지 알게 된 좋은 행동을 선택함
탐험을 너무 안 하면 더 좋은 전략을 발견하지 못한다.
활용을 너무 안 하면 이미 좋은 전략이 있는데도 계속 실험만 한다.
탐험 부족 → 지역 최적해에 갇힘
탐험 과다 → 성능이 안정되지 않음
Policy와 Value
강화학습에서는 두 가지 개념이 중요하다.
Policy
Policy는 상태에서 어떤 행동을 선택할지 정하는 전략이다.
→ 현재 상태 s에서 행동 a를 선택하는 규칙
미로에서 벽이 오른쪽에 있으면 위로 이동
상대가 공격적으로 나오면 방어 선택
Value
Value는 어떤 상태나 행동이 장기적으로 얼마나 좋은지 나타내는 값이다.
이 상태에 있으면 앞으로 보상을 많이 받을 가능성이 큰가?
이 행동을 하면 장기적으로 유리한가?
LLM에서 말하는 RLHF
LLM에서 자주 나오는 RLHF는 Reinforcement Learning from Human Feedback이다.
- 모델이 여러 답변을 생성한다.
- 사람이 어떤 답변이 더 좋은지 비교한다.
- 그 선호 데이터를 바탕으로 reward model을 만든다.
- 모델이 더 선호되는 답변을 하도록 조정한다.
여기서도 “정답 문장 하나”를 직접 주는 지도학습과는 다르다.
사람의 선호를 보상 신호로 바꿔서 모델을 조정한다.
다만 전통적인 게임 강화학습과 완전히 같은 상황은 아니다.
LLM의 RLHF는 언어모델을 사람 선호에 맞추기 위한 정렬(alignment) 기법으로 이해하는 편이 좋다.

한눈에 비교하기
| 학습 방식 | 라벨/신호 | 핵심 목표 | 대표 예시 |
| 지도학습 | 사람이 붙인 정답 라벨 | 입력에 대한 정답 예측 | 분류, 회귀 |
| 비지도학습 | 라벨 없음 | 데이터 구조 발견 | 클러스터링, 차원축소 |
| 반지도학습 | 일부 라벨 + 많은 무라벨 | 무라벨 데이터까지 활용 | pseudo labeling |
| 자기지도학습 | 데이터 안에서 만든 정답 | 사전 과제 해결로 표현 학습 | next token, MLM |
| 강화학습 | 행동 결과 보상 | 장기 보상 최대화 | 게임 AI, 로봇, RLHF |
어떤 문제에 어떤 학습 방식을 쓰는가
- 정답 라벨이 충분히 있다
- 지도학습 우선 검토
- e.g) 문의 유형 라벨이 10만 건 있음 → 분류 모델 학습
- 정답 라벨이 없다
- 비지도학습으로 데이터 구조 탐색
- e.g) 라벨 없는 문의 제목 수십만 건 → 클러스터링으로 주제 묶음 찾기
- 라벨은 조금 있고 무라벨 데이터가 많다
- 반지도학습 검토
- e.g) 라벨 데이터 1천 건 / 무라벨 데이터 20만 건 → pseudo labeling 시도
- 대규모 원본 데이터로 기본 표현을 배우고 싶다
- 자기지도학습 검토
- e.g) 대량 텍스트 → 다음 토큰 예측으로 사전학습 → 특정 도메인 작업에 파인튜닝
- 행동의 결과가 보상으로 주어진다
- 강화학습 검토
- e.g) 로봇 제어 / 게임 플레이 / 추천 정책 최적화
정리
- 지도학습은 정답 라벨을 보고 배운다.
- 비지도학습은 정답 없이 구조를 찾는다.
- 반지도학습은 적은 라벨과 많은 무라벨 데이터를 함께 쓴다.
- 자기지도학습은 데이터 자체로 문제를 만들어 배운다
- 강화학습은 행동의 결과로 받은 보상을 키우도록 배운다.
GitHub 댓글